Quantifying Cyber Risk | Part 2
By Asha Abraham
We’ve already covered common approaches to qualitative cyber risk analyses in the previous blog post and highlighted key differences between qualitative and quantitative assessments. Here we will look at how to actually quantify cyber risk. According to Factor Analysis of Information Risk (FAIR)1, cyber risk management is about making well-informed decisions and we need to be able to limit future loss events to within tolerances in the most cost-effective way. To do this we have to decide what risk scenarios to accept, remediate, transfer or avoid. We are looking to answer three main questions:
- What are the organization’s top cyber risks and how much exposure in terms of financial impact do they represent?
- Which cyber risk management investments matter most?
- Are the cyber risk investments enough or too much?
To answer these questions we will need to quantify cyber risk just like actuaries do. They have been studying and quantifying uncertain future events, especially those of concern to insurance, for centuries now! One of the ways to quantify cyber risk is through analytical models. Analytic models attempt to describe how a problem space works by identifying the key elements that make up the environment and then establishing the relationship between those elements mathematically. For e.g., speed = distance/time. These models use ‘Decomposition’ which refers to breaking things that are difficult to estimate, or for which you don’t have sufficient objective data, into their constituent parts. You can then make estimates of these factors to arrive at an estimate for the sought value. Strategy consulting firms like McKinsey now advocate the use of quantitative risk analysis for cybersecurity, and to place the risks in a common enterprise framework.2
FAIR is an open international standard and quantitative model that describes the required elements for measuring cyber or operational risk. The FAIR ontology represents a model of how risk works by describing the factors that make up risk and their relationships to one another. These relationships can then be described mathematically, which allows us to calculate risk from measurements and estimates of those risk factors.
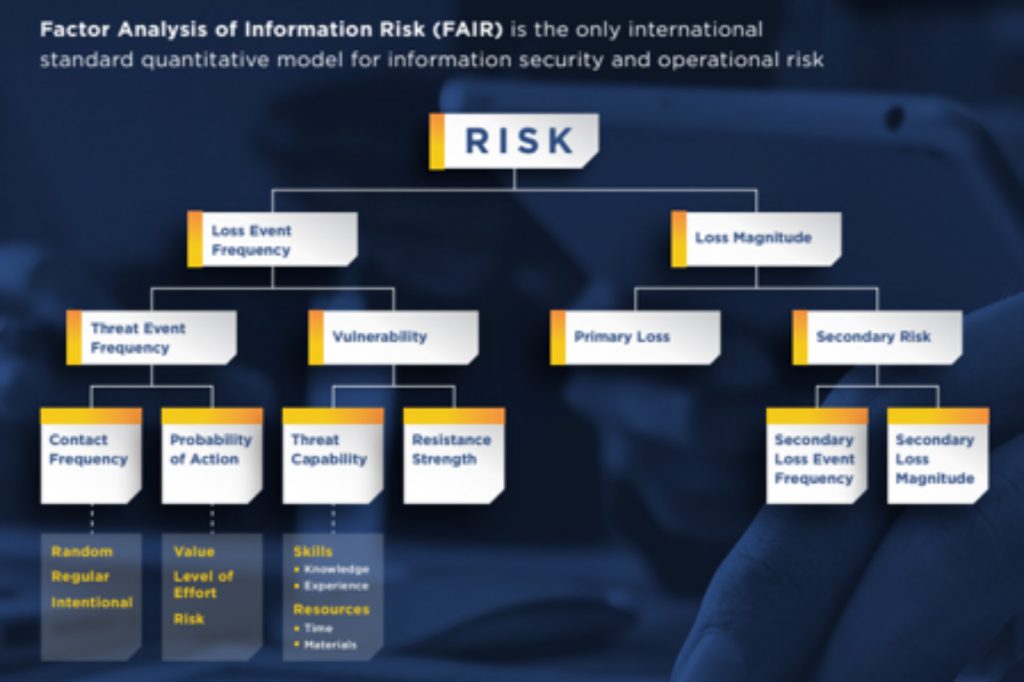
Each of the factors within the FAIR model that make up a risk scenario has a clear and logical definition within the standard that you can look up online here: https://www.fairinstitute.org/
According to FAIR there are four elements that you have to define for risk scenario scoping and these are – the asset, the threat against that asset, the effect the threat seeks to have on that asset (across the CIA: confidentiality, integrity and availability dimensions of the security triad), and optionally the method which describes how the threat will try to impact the asset. With these elements identified, measurements can be made that enable risk quantification and performance of what-if analysis, neither of which can be performed with control checklists or maturity model analysis.
All inputs into FAIR are probability ranges within a modified PERT distribution model. All ‘calibrated’ estimates input into the FAIR model have a minimum, maximum, most likely, and degree of confidence in the most likely. The confidence parameter adjusts the height of the distribution, allowing “weight” assignments to estimates. PERT distribution is a family of continuous probability distributions defined by the minimum (a), most likely (b) and maximum (c) values that a variable can take. Monte Carlo is the mathematical process behind the FAIR model and is its ‘what-if engine’. It approximates probabilistic outcomes by running multiple simulations using random variables within calibrated estimates and ranges.
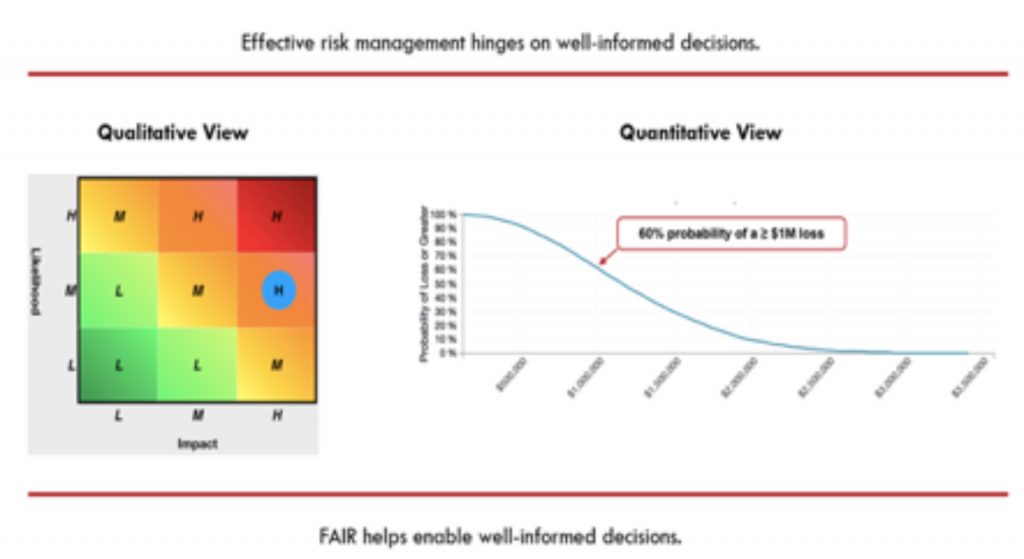
Risk analyses should not be considered predictions, nor should they be statements of what’s possible. Risk analysis inputs and results should all be statements of probability. Instead of using point estimates to say we will have 6 loss events over the next year, and each one will cost us $200,000, we define calibrated ranges for these inputs of probability and magnitude and let the Monte Carlo simulation model identify tens of thousands of probable outcomes. We then plot all of those outcomes on a graph and see where our total loss exposure is more likely to fall.
As the garbage in, garbage out (GIGO) principle states: flawed, or nonsense input data produces nonsense output or “garbage”. Truth be told, whether you are measuring risk with your gut or a supercomputer, the data you use is critical.Measurements don’t improve simply because they don’t apply analytic rigor and use high/medium/low as their risk measurements. At least with quantitative analyses there are well-established methods (e.g., PERT distributions, Monte Carlo simulations and calibrated estimation techniques) for dealing with sparse and uncertain data and reducing the effects of human subjectivity.
Qualitative and quantitative assessments have specific characteristics that make each one better for a specific risk assessment scenario, but holistically, combining both approaches can prove to be the best alternative for a risk assessment process. By using the qualitative approach first, one can quickly identify most of the risks to normal conditions, and then, use the quantitative approach on relevant risks, to have more detailed information for decision making.
Identifying and quantifying top risks within an enterprise should be an objective within any risk management program and this is fairly simple but not necessarily easy depending on the organizational culture. Once an organization identifies its top risk scenarios it can then focus on where to concentrate their risk management efforts by evaluating the value proposition of its risk reduction options, conducting cost-benefit analysis by comparing each option to its associated risk reduction potential.
Questions? We can help – ask us how.
References:
1 |
http://www.fairinstitute.org
2 |
https://www.fairinstitute.org/blog/white-paper-a-clarification-of-risks
https://www.risklens.com/blog/what-is-cyber-risk-quantification/
https://www.risklens.com/blog/think-you-dont-have-the-data-to-quantify-risk-think-again/